
Although I generally view most of Boost as bloatware that suffers from feature-creep, Boost MultiIndex provides a simple, STL-like container with different views, allowing fast data acess with multiple indexers.
Although the Boost documentation claims dramatic performance improvements for the multi_index container, relative to manually-maintaining multiple views, the tests were run with archaic compilers (GCC 3.4.5) and operating systems (Windows 2000). Inspired by this post, I decided to benchmark MultiIndex’s performance using Boost’s performance tests.
Methods
All tests were run with the following parameters, for GCC 6.3, Clang 3.8, and Fedora MinGW.
| Parameter | Value |
|---|---|
| CPU | i7-6560U, 2.20GHz |
| OS | Fedora 25 |
| RAM | 16 GB |
| Flags | -O3 |
| Wine | Wine-2.2 (Staging) |
Results
 |
| -------------------------------- |
 |
| -------------------------------- |
 |
| -------------------------------- |
 |
| -------------------------------- |
 |
| -------------------------------- |
 |
Conclusion
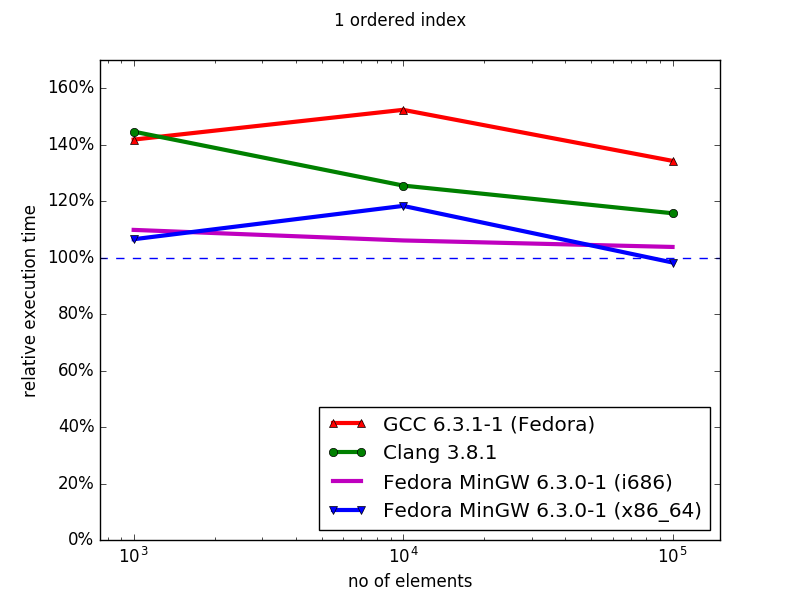
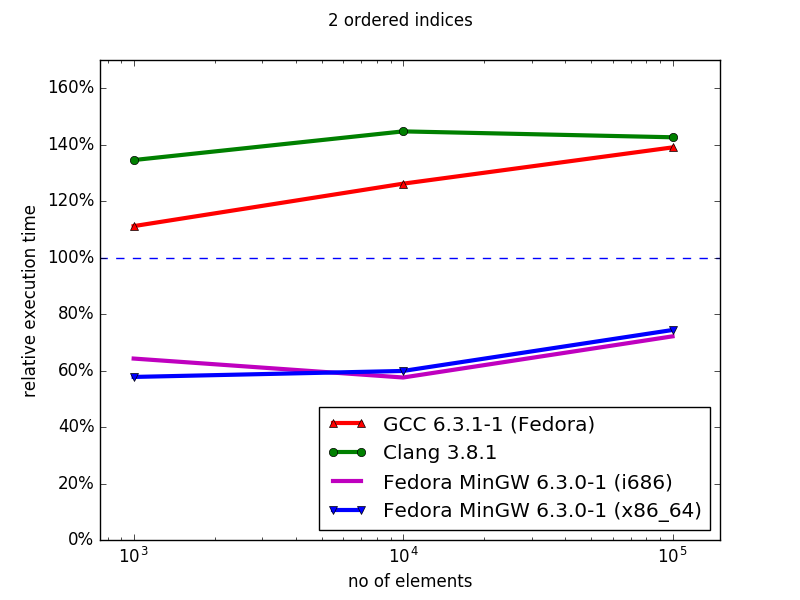
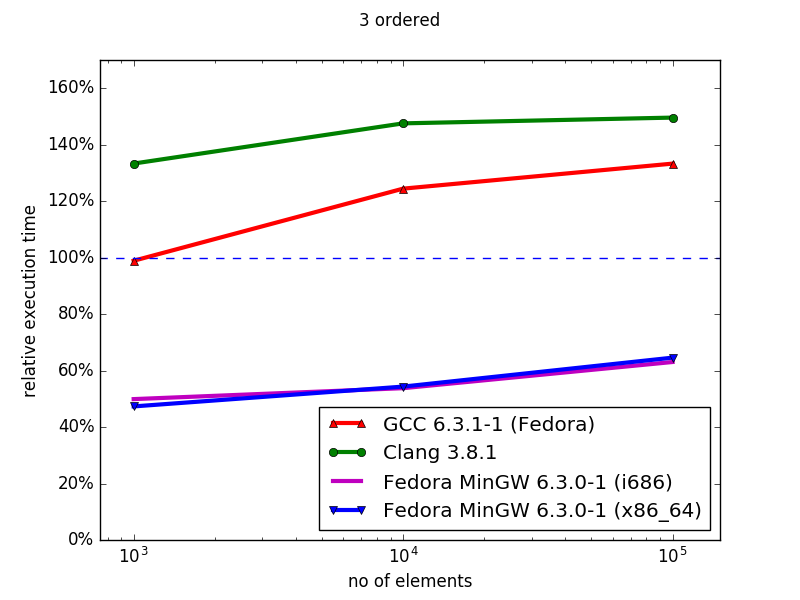
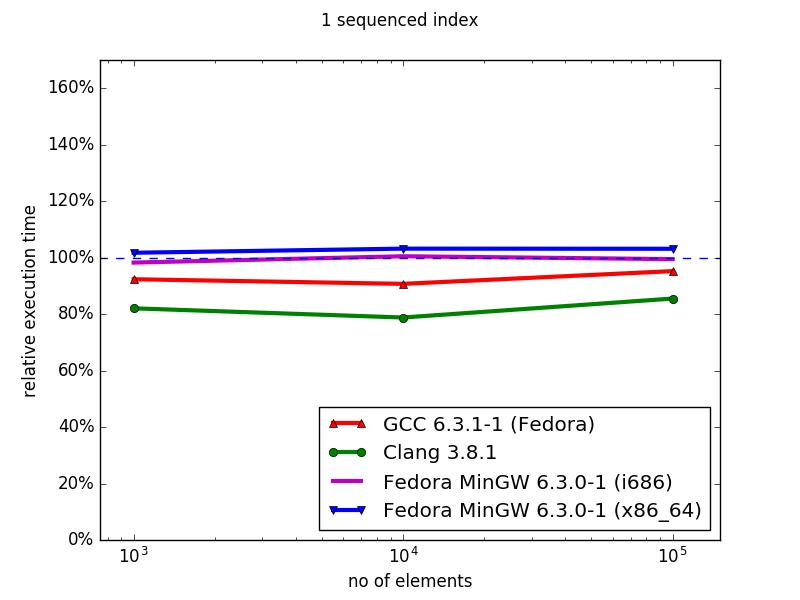
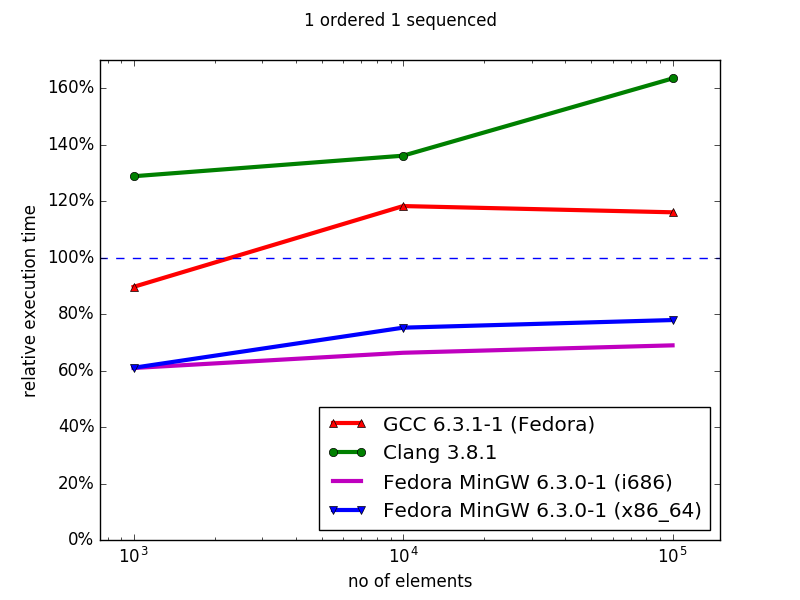
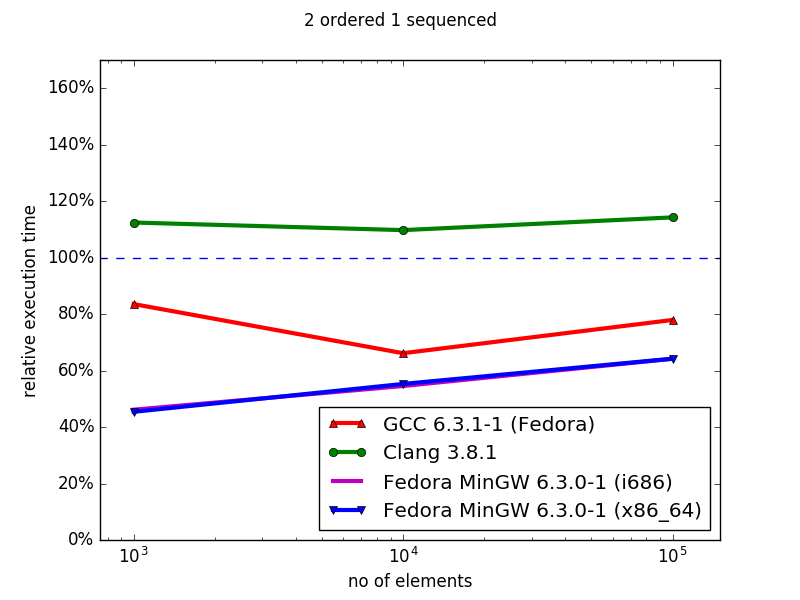
In general, the hashmap implementations (sequenced) of Boost MultiIndex are superior to the STL containers, both in memory (data not shown) and iteration time. Similarly, using MinGW, the ordered MultiIndex containers outperform their STL counterparts for both memory and iteration speed. However, with Clang and GCC, although the MultiIndex containers use less memory than their ordered STL counterparts, they have worse iteration times, and this performance gap increases with container size. Overall, MultiIndex is an excellent drop-in replacement for unordered containers, but suffers severe performance defects for ordered index iteration.
This gap between the ordered and unordered index iteration is trouble, since Boost’s documentation states precisely the opposite.